While looking for a quick drop in solution for a translation service in our projects, I found a lot of new AI startup offerings.
The requirement was
- Extensive language translation support, 30+ languages.
- Bulk API calls, with no rate limiting (this was to be displayed on Front-end)
- Inexpensive, as this would be a daily requirement (minimum 1k requests/day, translation)
Some solutions I saw charged around 100$+/month with rate limiting with max 2000 words per string translation.
I tested a few of them and found some don’t event cache requests ! So two same translation requests cost twice !
Unlike OpenAI, but it seemed expensive.
We can implement partial prompt/query caching on our side, but it is a whole another task in itself.
While I was exploring solutions, I came across LibreTranslate
It’s open-source, under aGPL license and free to use !
To run it locally on docker is QUICK
sudopower@m1 kiran % git clone https://github.com/LibreTranslate/LibreTranslate
sudopower@m1 LibreTranslate % ./run.sh 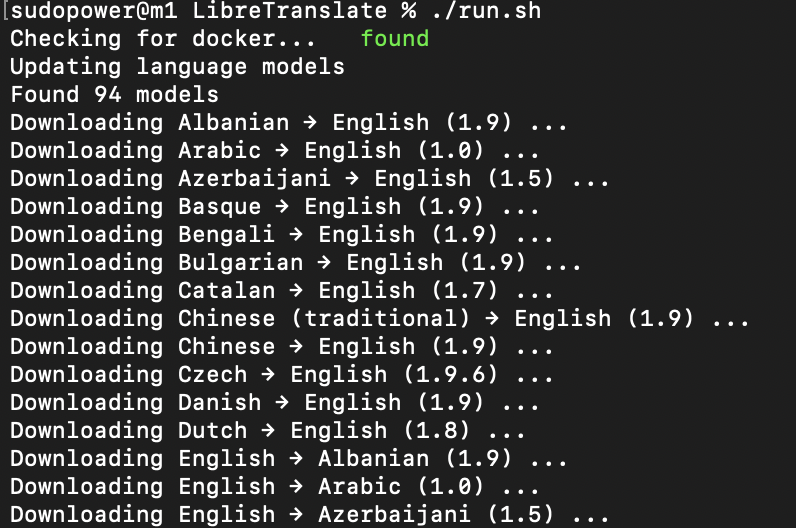
This will download all languages by default, but you can specify a list of languages you need
sudopower@m1 LibreTranslate % ./run.sh --load-only en,hi --port 6000
By default it will start your API server at http://localhost:5000, you may also specify port as arg to the script, as shown above (coz 5000 will most likely be used by some OSX process like AirPlay )
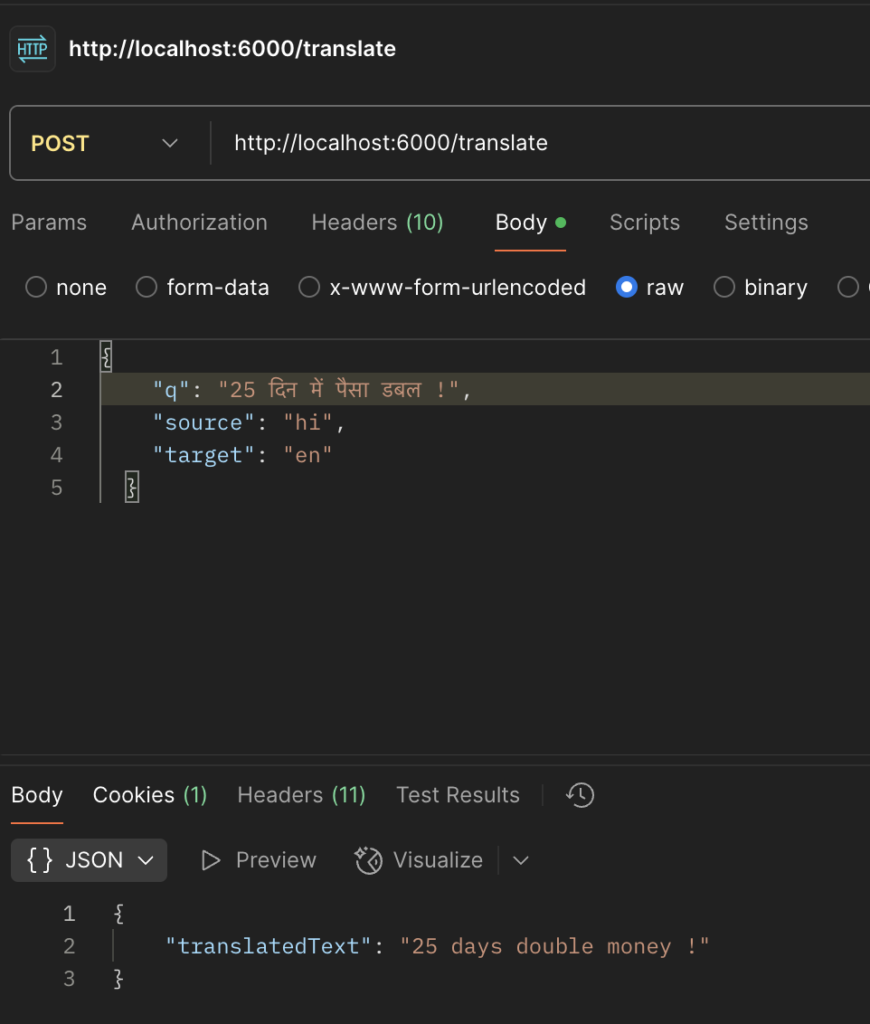
Supports auto language detection
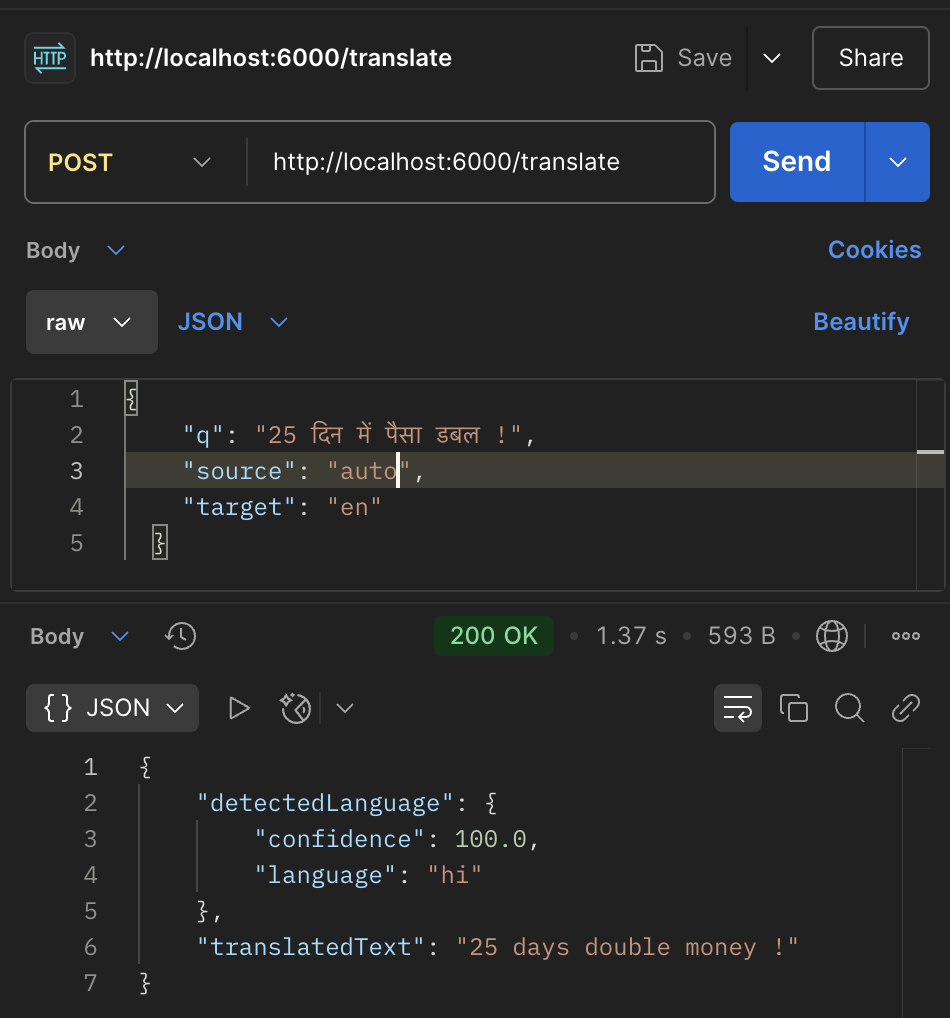
It has interfaces for Go, PHP, NodeJS, TypeScript, Ruby, Java and more so you can just define connection parameters and drop it in.
Built in support for updating the language models, which is based on OpenNMT
HELM charts included for kubernetes deployment !


Rough comparison with one third party paid solution shows decent results, even in case of edge cases like alphanumeric strings.

You also have a ready to use option upon buying their API key. But to be honest, it’s very quick setup to host your own instance.
You can also run it as a service, with API key authentication and rate limit users.
There are configuration options to run multiple instances to distribute load, store downloaded models on a persistent storage and share across instances to cache model downloads and save storage.
I might post some performance comparisons with paid services / models in future. But currently it seems to be at par, especially considering that it has no rate limit and can be scaled.