TL;DR: Anthropic dropped the visible context counter from Claude Code for a
cleaner UI. Without it I can’t tell how full the window is, so auto-compaction
fires when I don’t want it to. I built a status line that always shows it.
~100 lines of Python, no dependencies, full script in a gist.
The Goal
Claude Code shows a footer, but I wanted an always-on meter for the one number
that actually decides when a session falls apart: how full the context window
is right now. Percentage, a bar, and the last turn’s output tokens, colour-coded
so I notice before auto-compaction hits.
How the status line wires into Claude Code
Claude Code has a status line hook: you point it at any command, and on every
render it pipes a JSON blob describing the session to that command’s stdin.
Whatever the command prints becomes the status line.
1
2
3
4
5
6
7
8
| // ~/.claude/settings.json
{
"statusLine": {
"type": "command",
"command": "python3 /Users/kiran/.claude/statusline-context.py",
"padding": 0
}
}
|
The JSON on stdin includes the model, workspace, and, since Claude Code
v2.1.132, a native context_window object with the numbers already computed:
1
2
3
4
5
6
7
8
9
10
11
12
13
| {
"model": { "display_name": "Opus 4.8", "id": "claude-opus-4-8" },
"workspace": { "current_dir": "/opt/glass0" },
"context_window": {
"total_input_tokens": 15500,
"total_output_tokens": 1200,
"context_window_size": 200000,
"used_percentage": 8,
"current_usage": { "input_tokens": 8500, "cache_read_input_tokens": 2000,
"cache_creation_input_tokens": 5000, "output_tokens": 1200 }
},
"exceeds_200k_tokens": false
}
|
The key field is context_window_size: Claude Code reports the real window,
200000, or 1000000 for extended-context models, so the script never has to
guess a denominator per model. That single field is what makes the meter correct
across models instead of hardcoding 200k everywhere.
The script
The whole thing is ~100 lines of dependency-free Python. Read context_window,
compute a colour and a bar, print one line. It falls back to reading the
transcript JSONL for older Claude Code that predates the native field. The full,
copy-pasteable version lives in this GitHub gist.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| #!/usr/bin/env python3
"""Claude Code status line: live context / token-usage meter."""
import sys, json, os
DEFAULT_LIMIT = 200_000 # fallback only; CC reports the true size on stdin
def c(code, s): return f"\033[{code}m{s}\033[0m"
DIM, CYAN, GREEN, YELLOW, RED = "2", "36", "32", "33", "31"
def human(n):
if n >= 1_000_000: return f"{n/1_000_000:.1f}M"
if n >= 1000: return f"{n/1000:.1f}k"
return str(n)
def last_usage(path):
"""Most recent usage dict from the transcript (older CC fallback)."""
try:
with open(path) as f: lines = f.readlines()
except Exception:
return None
for line in reversed(lines):
if '"usage"' not in line: continue
try: obj = json.loads(line)
except Exception: continue
usage = (obj.get("message") or {}).get("usage") or obj.get("usage")
if isinstance(usage, dict) and usage.get("input_tokens") is not None:
return usage
return None
def main():
try:
d = json.load(sys.stdin)
except Exception:
print("🧠 ctx ?"); return
parts = []
model = (d.get("model") or {}).get("display_name") or "Claude"
parts.append(c(CYAN, f"⏺ {model}"))
cur = (d.get("workspace") or {}).get("current_dir") or d.get("cwd") or ""
if cur:
parts.append(c(DIM, f"📁 {os.path.basename(cur.rstrip('/')) or cur}"))
# Prefer the native context_window object (CC v2.1.132+): it carries the
# true window size (auto-detecting 1M models) and the current occupancy.
cw = d.get("context_window") or {}
ctx = cw.get("total_input_tokens")
limit = cw.get("context_window_size") or DEFAULT_LIMIT
out = cw.get("total_output_tokens")
if ctx is None: # fallback for older Claude Code
usage = last_usage(d.get("transcript_path", ""))
if usage:
ctx = (usage.get("input_tokens", 0)
+ usage.get("cache_read_input_tokens", 0)
+ usage.get("cache_creation_input_tokens", 0))
out = usage.get("output_tokens")
if ctx:
pct = cw.get("used_percentage")
if pct is None: pct = ctx / limit * 100
col = GREEN if pct < 50 else (YELLOW if pct < 80 else RED)
filled = min(10, int(pct / 10))
bar = "█" * filled + "░" * (10 - filled)
parts.append(c(col, f"🧠 {human(ctx)}/{human(limit)} {pct:.0f}% {bar}"))
if out:
parts.append(c(DIM, f"↑{human(out)} out"))
else:
flag = d.get("exceeds_200k_tokens")
parts.append(c(RED if flag else DIM, "🧠 200k+" if flag else "🧠 …"))
print(c(DIM, " · ").join(parts))
if __name__ == "__main__":
main()
|
Setup
1
2
3
4
5
6
7
| # 1. Save the script (from the gist)
curl -L https://gist.githubusercontent.com/sudopower/29e885cfc51487a992628edebe24951a/raw/statusline-context.py \
-o ~/.claude/statusline-context.py
chmod +x ~/.claude/statusline-context.py
# 2. Point Claude Code at it (settings.json snippet above)
# 3. Restart Claude Code; the meter appears on the next render
|
No dependencies beyond Python 3, and the status line runs locally, so it costs
zero API tokens.
Features
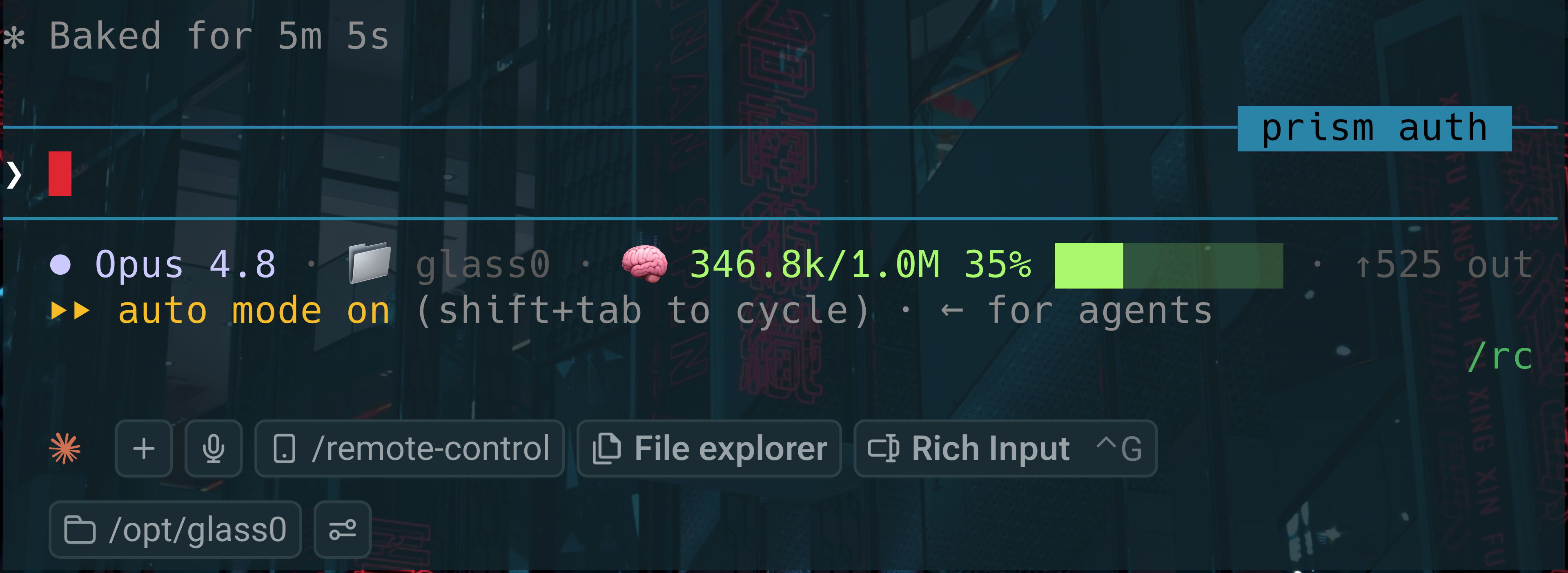
- Auto-detects the window. The header shot above is a 346.8k session on a
1M-context model, reading
346.8k/1.0M 35%. The size comes straight from
context_window_size, so there is no per-model table to maintain: switch to a
200k model and the denominator follows. - Colour-coded urgency. Green under 50%, yellow under 80%, red beyond, so a
filling window is visible at a glance. Here a 200k session sits at 53%, yellow:
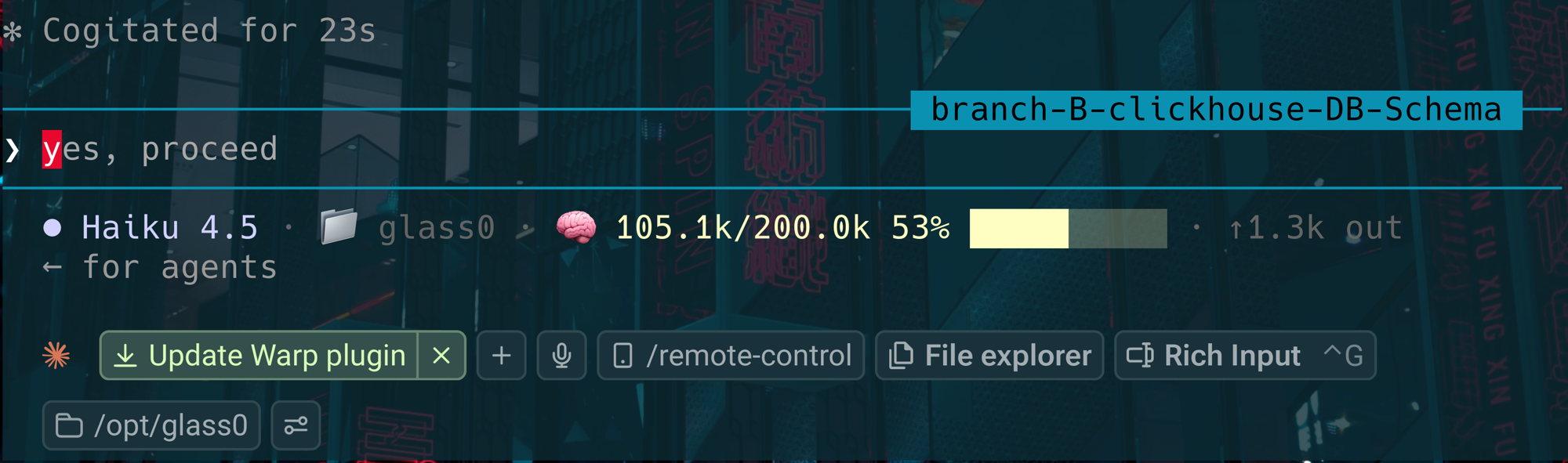
- Last turn’s output tokens (
↑… out), and graceful states: 🧠 … before
the first API call or just after /compact, 🧠 ctx ? on malformed input.
Why read the native field
The naive approach is to assume a 200k window and divide. That breaks the moment
you switch to an extended-context model. Reading context_window_size means the
meter is correct on any model without a per-model lookup table to keep in sync.
Claude Code already knows the real window, so let it tell you.