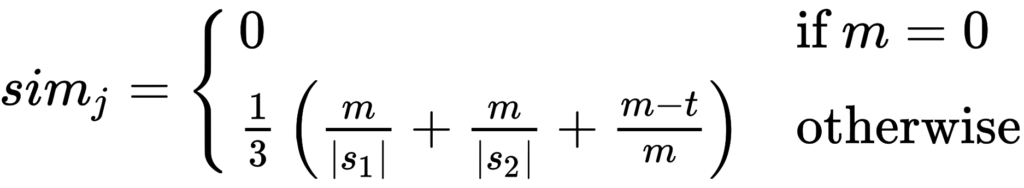
I came across this interesting algorithm while working on a task. I had two data sources for the team and player roster and wanted to match and merge them.
Consider two players Elon Musk and Colon Musk.
Now there might be a Colon Musk out there, with that name, but I bet not very successful.
But consider it’s a typo and say we’re pretty sure it’s a typo. Simple string matching would declare these two as “Not matching”.
How do we tell a computer to be kind of tolerant and consider them as same? How tolerant should the program be?
Introducing – String Distance
A string metric/distance is a metric that measures distance between two text strings for approximate string matching or comparison and in fuzzy string searching
https://en.wikipedia.org/wiki/String_metric
Instead of checking if they’re the same, we first check what’s different and how much. Then we prioritize/weigh the differences and come up with a similarity score. There are various algorithms with different implementations, that prioritize and calculate this differently. You can check them out here
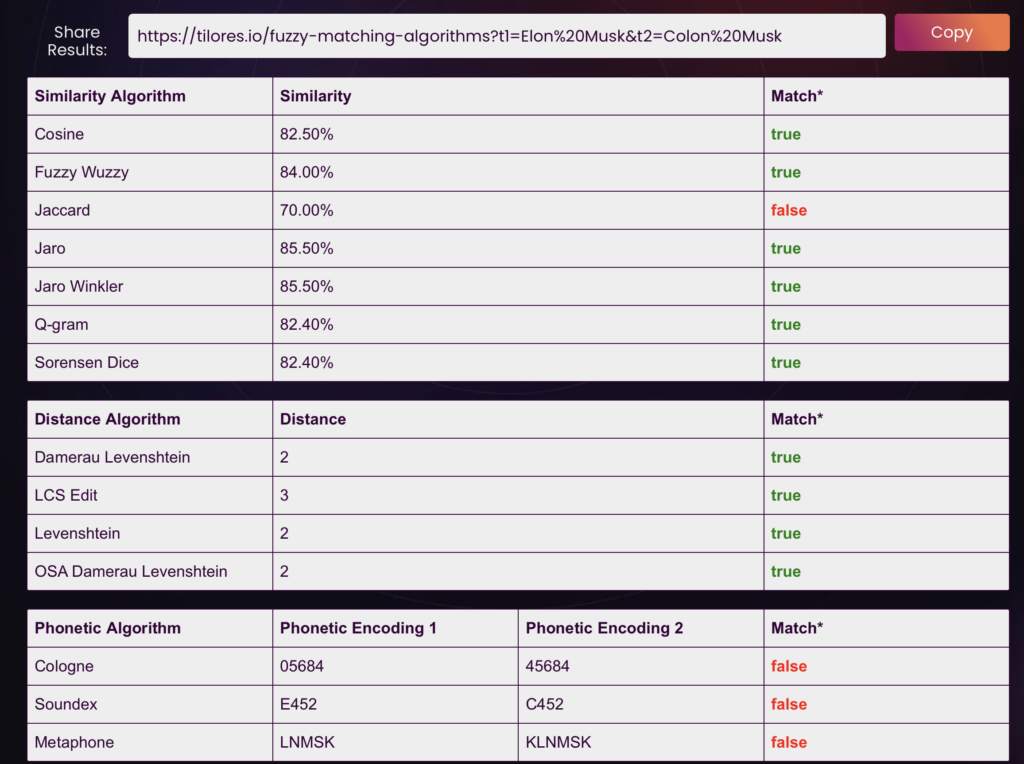
As you can see Jaro Winkler comes up with a similarity score of 85.5%, a score above 80% may be treated as matching.
Let’s try to understand in steps
Jaro Similarity

String lengths of S1 & S2 are 9 & 10
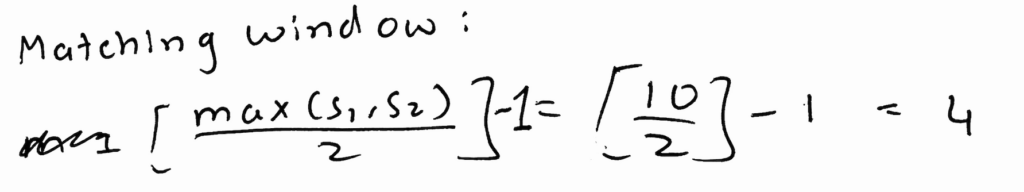
The matching window is the window in which we consider characters to match, i.e. if there were a “C” within 4 characters of “ELON MUSK” we would consider it as a matching character. In this case, our matching window is 4
Now we calculate the matching characters and the number of transpositions required for those matching characters

Transpositions are calculated as, half of the number of misordered characters, in this case, we have two E & C, so no of transpositions is 1
Plugging it all in
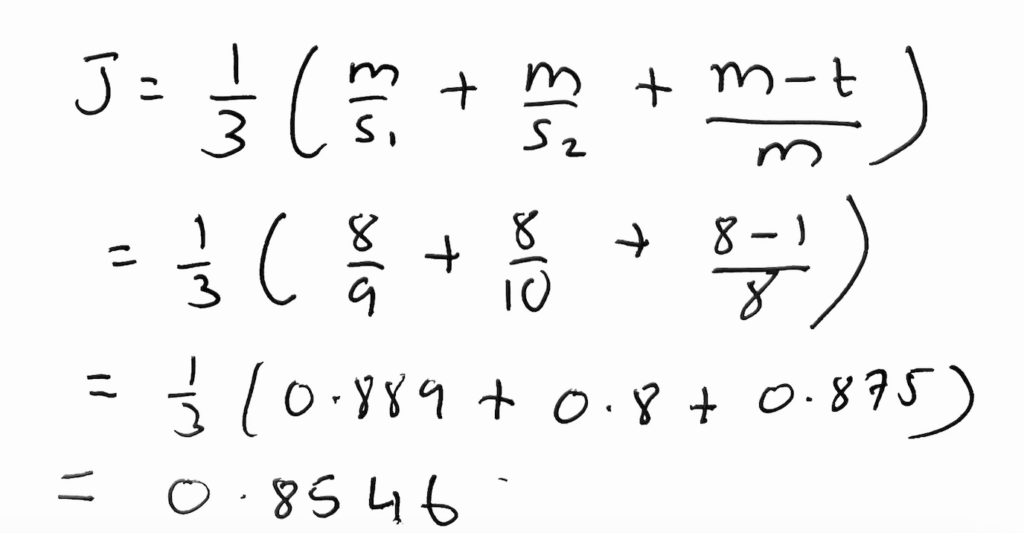
This is the Jaro Similarity for “ELON MUSK” & “COLON MUSK”, 85.46%
The Jaro-Winkler similarity gives preference to matching prefixes, i.e. based on a scaling factor, the similarity measure can be increased if two strings have a common prefix.
Why ?
In the case of names there’s a likelihood of having a common prefix or abbreviation, so in the case of “Mr Elon Reeve Musk” and “Mr Elon Musk” Jaro-Winkler similarity would be higher than Jaro similarity. Checkout here
Specialised algorithms were devised for Census calculation for matching and merging records based on names, addresses etc. Due to a large number of records these have to be efficient and prioritize certain characteristics specific to name matching.
Let’s calculate Jaro-Winkler similarity
Jaro-Winkler Similarity
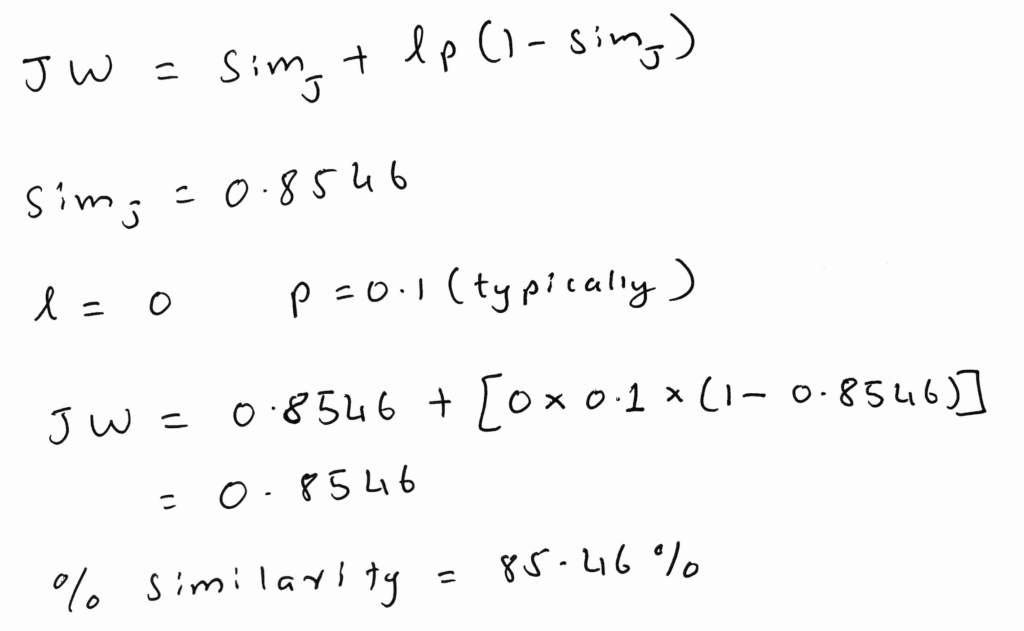
l is the length of the common prefix, which in this case is 0, if the strings were “MUSK ELON” & “MUSK COLON” the prefix would be 5, but the algorithm says the max limit of the common prefix is 4, which is understandable since most common prefixes like Mr, Mrs, Miss are usually upto 4 characters. But you can see how we can alter the implementation to our use case.
In our case, the Jaro & Jaro-Winkler similarity turns out to be the same
If the strings were “MUSK ELON” & “MUSK COLON” the Jaro distance would be 0.8755 and Jaro-Winkler similarity would be 92.5%
There are many more string matching algorithms. We also have phonetic matching algorithms, example Cologne phonetics algorithm assigns a phonetic code to strings, in the example above the phonetic code would not match but if the strings were “ILON MUSK” & “ELON MUSK” the phonetic codes would be an exact match. Try it out here